python提取多个文件的存在null速度廓线
背景介绍
在前面 python提取多个文件的案例中,只是遍历了全部有效数据,并提取其中两列数据,而如果数据存在NULL? pandas该如何处理?
在CFDpost处理怀来风电场数据的廓线时候遇到如下问题,速度廓线存在Null值,如下图所示
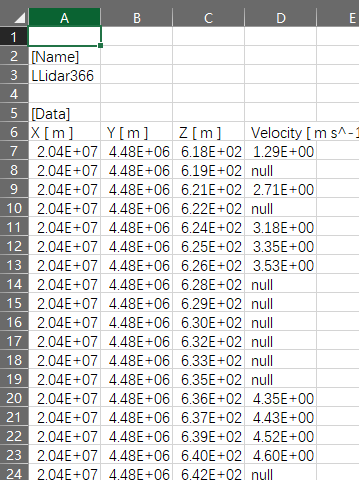{kind=link}
适合AIWIND计算出来的风电场机位点风廓线处理,存在空值
技术分解
- 遍历
- 提取所有非Null行 满足条件sd[sd.iloc[:, 3] != ’ null’] 即可。
- 减去对应海拔值
- 存储结果到对应的sheet表中
技术实现
import numpy as np
import pandas as pd
import os
headDir=r"C:\Users\yezhaoliang\PythonAIWind\pandasHuaiLaiProfile"
def get_files(path=headDir, rule=".csv"):
all = []
for fpathe,dirs,fs in os.walk(path): # os.walk是获取所有的目录
for f in fs:
filename = os.path.join(fpathe,f)
if filename.endswith(rule): # 判断是否是"xxx"结尾
all.append(filename)
return all
if __name__ == "__main__":
b = get_files()
writer=pd.ExcelWriter("Results.xlsx")
altitudesName=[]
for i in b:
them=i.split("\\")
sheetName=them[them.__len__()-4]+them[them.__len__()-3]+them[them.__len__()-1]
altitudesName.append(sheetName)
sd=pd.read_csv(i,skiprows=5)
## 去除Null行(注意空格,数字也一样处理)
sdNotNull = sd[sd.iloc[:, 3] != ' null']
startZ = sdNotNull.iat[0, 2] ## the third column at begin sequence you selected
squeezeZseries = sdNotNull.iloc[0:300, 2] - sdNotNull.iat[0, 2] ## 减去海拔值
temp1 = sdNotNull.iloc[0:300, 3]
temp2 = temp1.astype('str').str.strip() ##转换成字符串 然后去除左右空格
squeezeVelocityseries = temp2.astype('float64');
result = pd.concat([squeezeVelocityseries, squeezeZseries], axis=1)
result.to_excel(writer,sheet_name=sheetName,index_label=startZ)
writer.save()
writer.close()
#tags=os.path.split(i)
#print(os.path.join(tags[0],'done',tags[1]))问题发现
300个点得到的结果不依,高程不统一,为此专门提取500个点,可以帅选
改进main部分
if __name__ == "__main__":
b = get_files()
writer=pd.ExcelWriter("Results-compare-600.xlsx")
altitudesName=[]
for i in b:
them=i.split("\\")
secondPart=them[them.__len__()-2]
# sheetName=them[them.__len__()-3]+them[them.__len__()-2]+them[them.__len__()-1]
sheetName=them[them.__len__()-3]+secondPart[-9:]+them[them.__len__()-1]
altitudesName.append(sheetName)
sd=pd.read_csv(i,skiprows=5)
## 去除Null行(注意空格,数字也一样处理)
sdNotNull = sd[sd.iloc[:, 3] != ' null']
#squeezeZseries = sdNotNull.iloc[0:300, 2] - sdNotNull.iat[0, 2] ## 减去海拔值
temp1 = sdNotNull.iloc[0:1000, 3]
temp2 = temp1.astype('str').str.strip() ##转换成字符串 然后去除左右空格
squeezeVelocityseriesPre = temp2.astype('float64');
squeezeVelocityseriesPreNumpy = squeezeVelocityseriesPre.to_numpy();
temp3 = sdNotNull.iloc[0:1000,2]
temp4 = temp3.astype('str').str.strip()
squeezeZseriesPre = temp4.astype('float64');
squeezeZseriesPreNumpy = squeezeZseriesPre.to_numpy();
initialArray=squeezeVelocityseriesPre[squeezeVelocityseriesPre<=0.0].size
initialZ=squeezeZseriesPreNumpy[initialArray]
squeezeVelocityseriese = squeezeVelocityseriesPreNumpy[initialArray:initialArray+501]
squeezeZOriginial = squeezeZseriesPreNumpy[initialArray:initialArray+501]
squeezeZSeries = squeezeZseriesPreNumpy[initialArray:initialArray+501]-initialZ
result = pd.DataFrame({
'Velocity/(m/s)':pd.Series(squeezeVelocityseriese),
'Z-Z0/(m)':pd.Series(squeezeZSeries),
'Z/(m)':pd.Series(squeezeZOriginial)})
result.to_excel(writer,sheet_name=sheetName)
writer.save()
writer.close()
Related
叶昭良
Engineer of offshore wind turbine technique research
My research interests include distributed energy, wind turbine power generation technique , Computational fluid dynamic and programmable matter.