1米平方之python
从1月24号到2月7号的python学习汇总:
封装、继承体现代码重复,多态体现接口重复 万事万物结为对象,class Foo的Foo也是type语句生成出来的
fibonacci的yield过渡到生产者、消费者模式(串行体味到并行的感觉)
下一步可能接着学习多用户模式的socket通信以及mysql、django等学习
1-24 学习总结
- VIP14期之1:
python的工程应用案例,youtube,dropbox,facebook等,NASA等也在用
python的前景—薪资高的图
语言基础:
- 数据类型
- 流程控制 if-else if-elif-else while break
- 常用模块
- 函数、迭代器、装饰器
- 递归、迭代、反射
- 面向对象编程
- 购物车
- ATM
- 计算器
- 模拟人生
网络编程:
- socket
- 多线程 多进程
- 生产者消费者
- 堡垒机
- FTP
- 批量
- RAbibitMQ
- Redis、memcache、mongodb
Web基础
- html/css
- Dom
- JS
- jquery easyui angulaJS
- Ajax
- highChart
-
[ ] bootstrap
算法:(算法,才是计算机的精髓)
- 冒泡
- 二叉树
- 哈希
- 折半
-
[ ] 工厂模式、单例模式、享元模式、代理模式
自动化开发: 哪个地方用了什么算法!
PY WEB框架
- MVC
- 自行开发WEB框架
- Django Tornado Flask Bottle WebPy
- 中间件 ORM Cookie
- Restful API
- 权限管理
- BBS论坛(删掉)
-
[ ] Chatroom(删掉)
项目实战篇:
- 购物商城
- 主机管理+任务编排 + 运维审计堡垒机开发
- Nagios/Zabbix(已经开发了10几年了)监控产品(可能有用!)
- CMDB资产管理(自动化开发必须做的, 需要理解原理)
- 网站访问质量监测分析平台
- Docker
-
[ ] openStack(够呛)
为什么python? python的前景? Python的发展史? python2 or python3? https://www.cnblogs.com/alex3714/articles/5465198.html https://docs.python.org/3/
- VIP第二期
Python自动化开发之路 site:cnblogs.com https://www.cnblogs.com/flying1819/articles/8035554.html https://www.cnblogs.com/alex3714/category/770733.html
1-25号学习总结
no!
1-26号学习总结
数组操作 数组切片取出
def test_array():
names=["yzl","hh","hr","nb","em"]
print(f'names = {names}')
print(f'names[0] = {names[0]}')
print(f'names[1] = {names[1]}')
names[1]="New Times"
print(f'After names[1]="New Times" , names = {names}')
names.append("ending")
print(f'After names.append("ending") , names = {names}')
names.insert(2,"second")
print(f'After names.insert(2, "second") , names = {names}')
print(f' Before pop(2) names= {names}')
print(f' names.pop(2) = {names.pop(2)}')
print(f' After pop(2) names= {names}')
print(f' names.pop(1) = {names.pop(1)}')
print(f' After pop(1) names= {names}')
print(f' namees.index("hr") = {names.index("hr")}')
print(f' namees.index("nb") = {names.index("nb")}')
print(f' names[namees.index("nb")] = {names[names.index("nb")]}')
print(f'names[2]={names[2]}')
print(f'names[0]={names[0]}')
print(f'names[1]={names[1]}')
print(f'names[0:3]={names[0:3]}')
print(f'names[1:-1]={names[1:-1]}')深拷贝、浅拷贝、不拷贝
def test_ArrayCopy():
names=["zym","ys","lkp",["abc","def"],"qx","zb"]
## copy()是浅拷贝,只copy第一层,其它层走引用
## ***************第一种类型: 完全指针拷贝, 修改后完全相关***************
namesCopy=names
## ***************第二种类型: 浅拷贝 第一层值拷贝 第二层指针拷贝,修改后部分相关(第一层不相关)***************
# namesCopy=names.copy() ## 1. 数组copy等效于copy.copy(names)
# namesCopy=names[:] ## 2. 数组切片等效于copy.copy(names)
# namesCopy=list(names) ## 3. 工厂函数list(names)等效于copy.copy(names)
# namesCopy=copy.copy(names)
## ***************第三种类型: 深拷贝(完全不相关,各自一份内存)***************
# namesCopy=copy.deepcopy(names)
## 第一层是 值拷贝
names[2]="lukunpeng"
print(f'names={names}')
print(f'namesCopy={namesCopy}')
## 第二层是 指针拷贝
names[3][1]="123"
print(f'names={names}')
print(f'namesCopy={namesCopy}')
## 浅copy适用场景 夫妻共用一个财务账号 即夫妻姓名是不同,账号是共享 设计一个数据结构 [names,[saving,money]]
## 场景中考虑到内存部分共享,则考虑浅拷贝, 如果内存完全不共享,则为深拷贝
# 数据是否共享?
man=['Apple',['Saving',1000]]
woman=man[:]
woman[0]='Banana'
print(f'man= {man} \t women ={woman} ')
woman[1][1]=woman[1][1]-100 ### 花了100块钱,总存款就少了
print(f'Women spent 100 dollar \n\t man= {man} \t women ={woman} ')元组(tuple)可以理解为列表,但是他不可修改,只能查,有count和index,没有增、改,仿照列表即可,原则是看到元组后就认为数据内容不可改变!(元组工具类为set,用小括号括起来数据,列表是中括号)—–>数据是否可变?
def test_tuple():
## 元组内容不可变
product_list=[
('Ipod Watch',2000),
('Ipad', 7000),
('Iphone', 10000),
('Huawei P40', 8000),
('RongYao Magic3 ZhiZhen', 7400)
]
shoppign_cart=[]
print(f'product_list = {product_list}')
print(f'product_list[0,1] = {product_list[0][1]}')
salary=input('Input your salay: ')
if salary.isdigit():
salary=int(salary)
while True:
# for item in product_list:
# print(f'{product_list.index(item)} {item}') ## 回忆之前的知识点
## 更简捷方式 使用enumerate
## 新知识点1
for index,item in enumerate(product_list):
print(f'{index} {item}')
user_choice=input('Input series no what you wanna buy: ')
if user_choice.isdigit():
user_choice=int(user_choice) ## 新知识点2
if user_choice < len(product_list) and user_choice>=0: # product_list.count("ffff"): count是用来获取某个元素出现的次数
## 增加限制条件user_choice >0
if salary<product_list[user_choice][1]:
print(f'\033[1;34m money is not enough, please try again! \033[0m')
else:
print(f'got it, give you your gift {product_list[user_choice][0]}')
salary=salary-product_list[user_choice][1] ###更新你的工资
#salary -= product_list[user_choice][1] ###也可以简写
shoppign_cart.append(product_list[user_choice])
print(f'{product_list[user_choice][0]} has been added into the shoppign_cart; \n \033[1;32m how much you have now? {salary}, you can go on shopping \033[0m')
else:
print(f'\033[1;31m Warning! Please input the number less than {len(product_list)} \033[0m')
continue
elif user_choice=='q':
print(f'buy buy, your shoppign_cart has {shoppign_cart}')
print("shopping cart".center(50,'-'))
for index,item in shoppign_cart:
print(f'{index} -> {item}')
print(f'Your current balance is {salary}')
print(f'welcome back')
# exit() # exit直接退出这个程序, 会避免影响另外一个程序运行 先用break即可,退出无限循环
break
else:
print(f'\033[1;31m Invalid Option \033[0m')列表是最常用的数据类型之一,另外还有一个就是字典!(列表和字典都支持数据结构嵌套) 字典用大括号表示,工具类函数式dict
1-27号学习总结
元组是不可修改的列表 字符串具有不可修改特性
大部分时间我们都是在写函数,而不是写类,当我们觉得一直写函数的方式来解决问题,但是效率不高,于是我们才写了类,我们写了模块。
1月28号学习
以色列人均看书64本 中国人均看书4本(没有看书的习惯)
看书能够改变一个人的气质,气质表现为谈吐,与挣多少钱无关。
养成看书的习惯!《追风筝的人》:阿富汗 一个人 追风筝 —-书中自有黄金屋 书中自有颜如玉—-
1月29号学习
可以不用智能手机,可以每天多读书 flush才有效果!
for i in range(20):
sys.stdout.write('#')
sys.stdout.flush()
time.sleep(0.1)寻找人生的价值,创造价值(create value) reset, python 无所谓,人生无所谓 价值与否,在于个人,平常心即可!
旅行者1号视角看到的地球只是淡蓝色的一点,而在淡蓝色的一点曾经出现过君王、孔子、武藤兰、马云等。平常心即可
痛苦是因为对于无能的愤怒,有钱可能可以减轻一些痛苦。
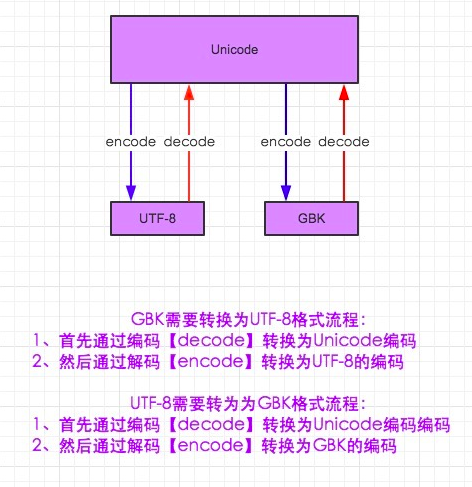
gb2312只支持几千个汉字 gb18030 2万多个万字 后来又出现了gbk!
日本、韩语也都有!
Unicode兼容世界语(中英文都占2个字节, Ascii占1个字节) 也就是一个英文文档是2MW,如果存为unicode的话,则为4MW
为此又出现了UTF-8,统一unicode和ascii码! 凡是中韩系采用Unicode,而英系则用ascii码
需要明白文件编码 和程序编码的区别
我们每一个文件打开、显示都会有一个编码, 比如中文兄系统的大部分文件都是按照gbk编码的,但是如果程序默认解析通过utf-8显示该类文件,那么就需要事先decode(‘gbk’),转为unicode,然后再encode(‘utf-8’)转成utf-8编码源程序,最后再由程序去解释
- 要记住每一个文件都有编码,可以采用记事本查看, 如果是gbk编码文件,导入到pycharm需要追加 #--coding:gbk--
- 要记住所有程序文件的中文都是Unicode(无论在文件编码指明了gbk或者韩语、日语等),也就是说无法使用decode(),但是可以使用encode(‘gbk’), encode(‘utf-8’)等。
ubuntu中文件转换可以使用 iconv 命令,该命令的格式如下: iconv -f 文件编码格式 -t 想要转换的编码格式 要编码的文件名 -o 编码之后的文件名 iconv -f ‘gbk’ -t ‘utf-8’ file.c -o filenew.c 这样就可以把中文编码的源程序,变成utf-8编码的源程序,发送给c编译器也能编译通过。 pycharm默认底部有一行显示utf-8(任何编辑器都会有默认的编码形式)
VIP第四期 python回顾与整理 https://blog.51cto.com/xpleaf/1763071
函数和过程的区别: 在python当中,过程就是没有定义return的函数。 但是python会给函数一个None返回值做为过程返回值(隐式执行)
平常心是一种很好的学习心态,镂空心态。
装饰器:本质是函数,每个函数都有目的,装饰器的目的就是为了装饰其他函数,附加其他功能。 装饰器原则:不能修改装饰的函数, 不能被修改函数的调用方式 装饰器对被装饰的函数完全透明,用了这个函数的人,并没有发现这个函数被装饰了
1月30号学习
斐波那契数列是生成器串行算法 生产者-消费者模式是生成器并行算法
## 生成器测试
## 生成器串行
def fib_max(max):
n,a,b=0,0,1
while n<=max:
yield b ## 生成器生成 用于返回需要从算法里面中间计算得到的值 当前状态值!
a,b=b,a+b
n=n+1
return '*--done--*'
def test_generator():
print(f'a=[1,2,3,4,5,7,8] = {[1,2,3,4,5,7,8]}')
print(f'[i*2 for i in range(1,10,1)] = {[i*2 for i in range(1,10,1)]}')
print(f'(i*2 for i in range(1,10,1)) = {(i*2 for i in range(1,10,1))}')
## 生成器小括号,一般是存储算法到内存,而不是像列表把所有数据导入内存中
g=fib_max(6)
while True:
try:
x= next(g)
print(f'g= {x}')
except StopIteration as e:
print(f'Generator exception return value {e.value}')
break2月1号学习
单线程下的并行(异步)程序(nginx底层逻辑过程) —–协程开发! 注意下面程序必须先执行next,因为我们需要让程序执行到yield 函数中
## 生成器并行: 生产者-消费者模式
def consume(name):
print(f'\033[31;1m Inside consume:\033[0m 准备吃包子了{name}')
while True:
baozi=yield
print(f'\033[31;1m Inside Consume:\033[0m 包子{baozi}来了,被{name}吃了')
## 生成器并行: 生产者-消费者模式
## 不要小瞧这段代码,它是异步IO的雏形,nginx的前身,nginx为什么效率那么高,因为它是异步
## 虽然当前代码依然是串行,但由于切换不同角色,且执行速度快,所有有点看起来是并行程序。
def producer(name):
print(f'\033[1;32m 老子{name}准备做包子了 \033[0m')
c1=consume('Wen Zongli')
c2=consume('Zhou Zongli')
c1.__next__()
c2.__next__()
for i in range(10):
time.sleep(1)
print(f'\033[1;33m 做了1个包子 分成凉拌\033[0m')
c1.send(i)
c2.send(i)我们已经知道: 可以直接作用于for循环的包括以下两类数据:
- 集合类数据,比如list,dict,tuple,set,str,file等(for I in file是迭代器对象 iterator对象,这就是为什么他快得原因 for I in f)
- generator类数据,
这些可以直接作用于for循环的对象,统称为可迭代的对象,或者叫做可循环对象, 可以使用isinstance(),来判断对象是否可迭代。
from collections.abc import Iterable
isinstance('[]',Iterable)
isinstance('{}',Iterable)
isinstance('abc',Iterable)
isinstance('set(1,3,5)',Iterable)
isinstance('(abc)',Iterable)生成器除了被for循环调用外,即Iterable功能,他还可以被next()反复调用并不断返回下一个值。 我们把可以被next()函数调用并不断返回下一个值的对象成为迭代器:Iterator
可以使用isinstance()判断一个对象是否是Iterator对象
from collections.abc import Iterator
isinstance('abc',Iterator) ## false
a= [1,2,3]
dir(a)## 查看a可以调用的所有内部方法 dir是python中一个相当重要的命令
isinstance('(x*2 for x in range(10))',Iterator) ## Truelist,dict,str虽然是一个Iterable对象,但却不是Iterator对象 但是可以通过iterator的一个内部函数进行变换
之所以list,dict,str不是一个Iterator对象,是因为Iterator对象本身是一个数据流对象,可以被next函数反复调用,并不断返回下一个数据(值也是可以的),直到没有数据抛出Stopiteration错误,可以把这个数据流看做一个有序序列,但是我们却不能知道这个序列的长度,只能不断通过next函数按需计算,得到下一个数据。 所以Iterator的计算是惰性的,效率高!只有在需要的时候才会返回下一个值。 即Iterator甚至可以表现无限的自然数,但是list就不可以。
from collections.abc import Iterator
isinstance('iter(abc)',Iterator) ## false
a= [1,2,3]
isinstance('iter(a)',Iterator)Iterable很重要的知识点!类似于java的Collections的作用! 内建函数 https://docs.python.org/3/library/functions.html?highlight=built
compile相当不错,增加了动态执行python代码段的功能。
其实直接exec或者eval也是可以执行,不需要compile
## compile and exec
code="for i in range(10):print(i)"
c=compile(code,"",'exec')
exec(c)
code2="1+2+3*4/29.2"
c2=compile(code2,'','eval') ## eval其实可以直接调用
eval(c2)
## compile甚至可以变到更大的代码段,类似动态导入的过程! 动态import代码的过程!## python一切数据类型的根都是由type产生的
## json序列化带来的好处是可以在不同语言的代码相互转化,逐步替换xml
https://www.cnblogs.com/alex3714/articles/5143440.html 软件目录结构: Foo/ bin/ foo ##启动脚本 foo/ init ## 凡是有init的文件,叫做包,没有init叫做目录 main.py conf/ init ## 凡是有init的文件,叫做包,没有init叫做目录 settings.py docs/ setup.py ## python setup.py .. requirement.py ## 依赖关系 readme.md https://www.cnblogs.com/wupeiqi/articles/4963027.html
软件目录结果 https://github.com/pallets/flask/blob/main/setup.py
foo会去调用foo目录下和conf目录下的模块
2月2号学习
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
- 自定义模块
- 内置模块
- 开源模块
python标准库函数介绍: https://docs.python.org/3/library/index.html 操作系统模块:https://docs.python.org/3/library/os.html 解释器系统模块:https://docs.python.org/3/library/sys.html 文件模块: https://docs.python.org/3/library/io.html 进程管理模块:https://docs.python.org/3/library/subprocess.html configparser: https://docs.python.org/3/library/configparser.html 日志模块: https://docs.python.org/3/library/logging.html loguru: https://loguru.readthedocs.io/en/stable/ https://cuiqingcai.com/7776.html https://segmentfault.com/a/1190000040911280 https://cloud.tencent.com/developer/article/1664382 json模块:https://docs.python.org/3/library/json.html 多线程模块:https://docs.python.org/3/library/multiprocessing.html 内置函数: https://docs.python.org/3/library/functions.html
很特别的抽象语法树模块: https://docs.python.org/3/library/ast.html python关键字: https://docs.python.org/3/reference/lexical_analysis.html#keywords
idea快速查看一个文件有多少代码和功能(CTRL+H12),Alt+F7也相当好用
https://github.com/Delgan/loguru 好用的日志框架
加速python安装包安装速度
放在`c:/users/{username}/pip/pip.ini`
[global]
timeout = 60
index-url = http://pypi.douban.com/simple
trusted-host = pypi.douban.com在进行程序设计的时候,注意程序解耦、模块解耦、程序的可复用(相互独立、最小化原则) 要不断思考、凝练! 思考每段程序的作用。
思考的小技巧:把相似的地方提取到一个函数中。 从最终使用角度去反推你的设计,你最后要怎么用这个程序,哪种方式最方便
transaction(tran_type,account,amount,logger)或者从测试的角度出发,transaction(还款,谁,2000,logger) transaction(提款,谁,20000,logger) transaction(转账,谁,转账账户,10000,logger) 从测试指导设计也是一个不错的思考方式! 从使用者的角度去设计一个好用的程序!(要写下来才有用)
可以把我梳理集团科技项目管理平台的业务经理经验给大家分享一下,干了多少张业务图,按照流程的先后顺序、涉及到多少相关人员、需要形成多少新数据、最终还得做业务蓝图评审。
所以设计一个程序应该是从业务开始梳理,从蓝图获得编码的基准,然后才是编码,也就是前期会形成很多uml设计图、类图-时序图等,指导编码。
而如果想要省调这堆设计图,那么也就是你的脑中得有这些流程图,图在这里很重要,他体现着你对代码的布局,体现着代码的运用场景,体现你对代码的谋篇布局。
能不能把主要规律用_几条简单的公式写出来,就是懂不懂产品内在规律_。 三个基本公式:(无论你的程序怎么设计,都得解决这些等价关系, 所以等价关系决定着程序的设计) 取款:user1=user1-amount 还钱: user1=user1-借钱*(1+利息) 转账: user1 = user1 -amount; user2=user2+amount(转账手续费 金卡不需要等)
想知道数,是想要知道产品的性能想知道图,是想知道产品的运用场景想知道报告,是想知道产品的可行性
数*一定冗余裕度(1+20%)= 保守设计范围 交易就是买卖的意思!
看源码速度快与慢取决于你脑海里生成业务场景的快与慢!
2月3号学习
from loguru import logger ## 好处是加快logger执行速度,同事logger 也可以起个别名,如果直接import loguru, 调用多次logger, 还得多次loguru.logger.info。
"""
import 本质是路径搜索 类似DNS 路由
会把对应文件模块解释一遍
"""
"""
包的本质是存储多个模块,就多个py文件,一个包里里面必须有一个__init__.py文件
专业表示:逻辑上组织模块是包
逻辑上组织python代码(比如类、变量、函数、关系等)叫做模块
导入模块的本质是把模块文件解释一遍
导入包的本质是把模块的__init__.py文件执行一遍(run __init__.py)(与模块有所区别)
run __init__.py 很关键, 也就是以后导入包的模块通过,包同级导入,即相对路径导入
比如: core目录下,我在__init__.py执行 from . import testModule,test_pickle_loads 等,但是不能import testModule, 因为import
此时是绝对导入,不具有以当前包围相对坐标系的功能。
所以run __init__.py的理解很重要 .代表的是__init__.py所在路径
"""
def sayHelloInModule(name):
logger.info(f'hello world Mr|MRs{name}')
## sys.path就是一个列表 list 环境变量组合 想要import模块或者包必须保证模块或者包在我们的sys.path目录下能够找到,所以sys.path类似于操作系统的环境变量
# logger.info(f'current sys.path = {sys.path}')面向对象介绍 特性 class object 世界万物都可分类, 凡是对象都有种类,存在一定的范畴 只要是对象,就有分类,就有属性 多态表现为,有一份工作,A\B\C三个人来做,效果不一样,在于他们都能做这份工作,但是工作实现的效果不太一样,有好有坏!工作就是一个接口,ABC都实现了工作接口
在历史长河中,有很多人都能做领袖,但是领袖执行的效果、统帅的效果各有不一,有的是暴政,有的是勤政,有的是昏政,领袖是一种接口,不同君王都实现了该接口,但是统帅的效果不一。
第一次还不太习惯用python写面向对象程序,还得多写几遍。
类变量共用内存,节省开销(放在类中的变量,而不是方法中) 析构函数:def del(self) (del对象的时候 出现 f.close()出现) python有自动回收机制。
class Man(People,Relation):
super(Man,self).__init__(self,name,age) <--super解决多继承问题(java只有单继承)python3是广度优先(新式类和经典类都是广度优先),python2是深度优先(多继承有用)(经典类),py2的新式类也是广度优先
## 经典类 多继承优先找的是临近类
class A:
pass
## 新式类 多继承优先找的是临近类
class A(Object):
pass2月4号学习
我觉得每个人都应该学习一门编程语言。学习编程教你如何思考,就像学法律一样。学法律并不一定要为了做律师,但法律教你一种思考方式。学习编程也是一样,我把计算机科学看成是基础教育,每个人都应该花一年时间学习编程。
“I think the greatest value of learning how to think…. I think everybody in this country should learn how to program a computer, should learn a computer language, because it teaches you how to think. I view computer science as a liberal art. It should be something everybody takes in a year in their life, one of the courses they take is, you know learning how to program.”
面向对象编程 https://www.cnblogs.com/alex3714/articles/5188179.html
- 当py文件独立运行时候,该模块文件内的name字段即为main
- 当py文件以import运行时,该模块文件内的name字段即为导入模块名字
https://www.cnblogs.com/rianley/p/9013905.html
2月5号学习
任务监控学习: https://github.com/giampaolo/psutil ### 知识点: 模块名和类名不能一致,否则报错 import失败, 即 User模块文件,不能包含User class,否则导入User类失败
2月6号学习
ATM+购物车—> 人 — 钱 — 物 —->管人 manager — 管钱 atm — 管物 购物车 —->管权 — 管物
我们知道,封装通过模块设计方法(方法),隐藏代码实现细节(效果),从而使得代码模块化(最终效果) 继承可以通过已实现的代码模块(类) 封装和继承的目的都是为了代码重用 (但是能用组合的形式尽量用组合,比如变形金刚有手、脚、头等多个部位组合而成) 那么多态? 多态是允许子类类型的指针赋值给父类(如果子类产生新的方法,那只能采用父类进行定义) 一个接口,多种实现, 多态的目的就是为了解决接口滥用问题,实现接口重用(区分代码重用)
@property的作用是把动作实现细节隐藏,只返回一个状态,但其实property变量内部执行了一堆外部API、并做了呈现。
print(f’cat1“s类型是{type(cat1)}’) ## 知识点 java一切对象皆对象,对象都有类,类也是一种对象,类的归属是Type print(f’Cat“s类型是{type(Cat)}’)
类的方法一般都有一个self字段。
type又称类的类
def hell(self):
print(f'hho')
Foo=type('Foo',(object),{'talk':hell}) ##object也可以省略,当前为新式类写法
f=Foo() ## Foo 其实是type的对象
f.talk() ##等价于调用hell()增加init函数
def hellInit(self):
print(f'hho {self.name}')
def __init__(self,name,age):
self.name=name
self.age = age
FooInit=type('FooInit',(object,),{'talk':hellInit,
'__init__':__init__}) ##object也可以省略,当前为新式类写法
f2=FooInit('Ale',33)
f2.talk()面向对象的起源是type(一切皆对象) class类由type实例化得到。 https://www.cnblogs.com/alex3714/articles/5213184.html
类的生成 调用 顺序依次是 new –> init –> call 一般不写new,只是调用父类的new方法
通过字符串映射或修改程序运行时的状态、属性、方法, 有以下4个方法
通过反射setattr实现内存动态装配
d=Dog("xiaowang")
choice=input(">>").strip()
## 简化很多代码
if(hasattr(d, choice)):
getattr(d,choice)
else:
setattr(d,choice,bulk)
func=getattr(d,choice)
func(d)
# setattr(d,"newFunction",bulk)
# d.newFunction()异常不处理,程序会崩溃,比如除数为0,key不存在,文件不存在等 try except就会正常结束
socket编程,其实是指传输层编程,它基于ip网络程,实现了TCP和UDP协议, 在socket之上可以构建http、mqtt、weixin、qq等通信应用程协议 https://www.cnblogs.com/alex3714/articles/5830365.html
socket其实就是tcp/ip 和udp协议的包装,包含收发过程 各种网络协议都基于socket!
最基本的业务流程确认没问题:服务器端导入socket包,引入tcp或者udp协议,创建端口(bind),建立监听(listen),等待链接,接受(accept)和发送send和接收recv。
客户端导入socket包,引入tcp或者udp协议,连接端口connect,发送send和接收recv。
socket其实就是一个网络文件协议!bufferByte进行传递
反射是支持编程语言从字符串获取内存地动作能力 __import__是支持模块动态导入的能力,即import是类似宏的功能,先会解析import vars的vars的内容,然后再进行import (from .. import 不变量引入,
## 前提,我只知道模块名字的字符串形式,如何动态导入类,并通过反射获得模块内的类、方法等
mod=__import__("lib.aa")
print(f'mod={mod}')
instance = getattr(mod.aa,"C")官方建议使用importlib更方便些,不建议使用python解释器内部使用的import_
叶昭良
Engineer of offshore wind turbine technique research
My research interests include distributed energy, wind turbine power generation technique , Computational fluid dynamic and programmable matter.